

Flux Training und Generierung leicht gemacht
Kapitelübersicht
Einleitung
Willkommen bei Flux Model Forge, einem Diplomprojekt, das die kreative Nutzung von KI-Modellen auf eine neue Ebene hebt. Unser Ziel ist es, Kunststile und Zeichenmethoden mithilfe der LORA-Methode (Low-Rank Adaptation) präzise zu replizieren und individuell anzupassen. Dabei setzen wir auf die Flux-Technologie, um die Effizienz und Flexibilität des Trainingsprozesses zu maximieren.
Dieser Guide bietet eine Schritt-für-Schritt-Anleitung – von der Einrichtung der GPU-Pods bis zur Nutzung leistungsstarker Tools wie ComfyUI und FluxGym. Egal ob Sie Anfänger oder erfahrener Nutzer sind, hier finden Sie alles, was Sie brauchen, um Ihre eigenen kreativen Projekte mit KI umzusetzen.
RunPod Setup
1. Konto einrichten
Gehen Sie auf runpod.io und laden Sie Ihr Konto mit mind. 100$ Guthaben auf.
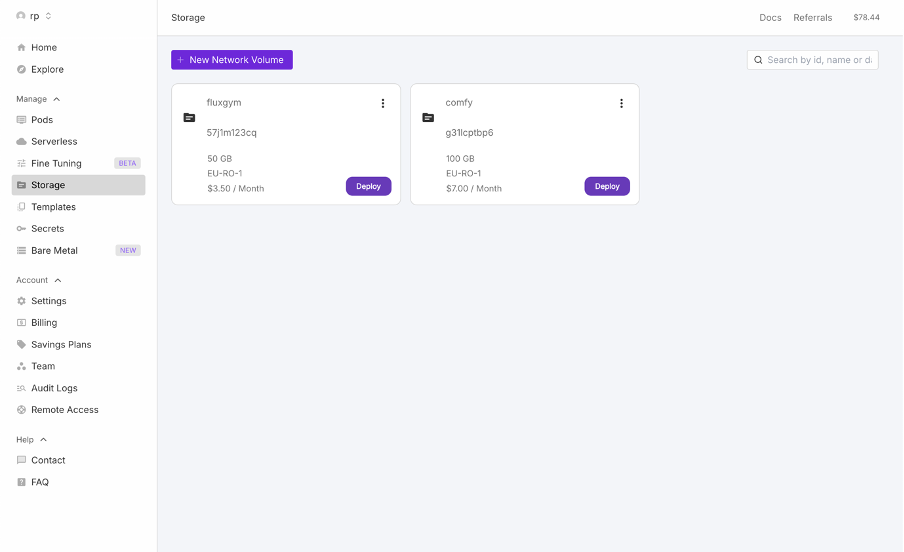
2. Network Volume erstellen
ComfyUI: 100 GB
FluxGym: 50 GB
Data Center: EU-RO-1 (beste RTX 4090-Verfügbarkeit)
3. GPU-Pod deployen
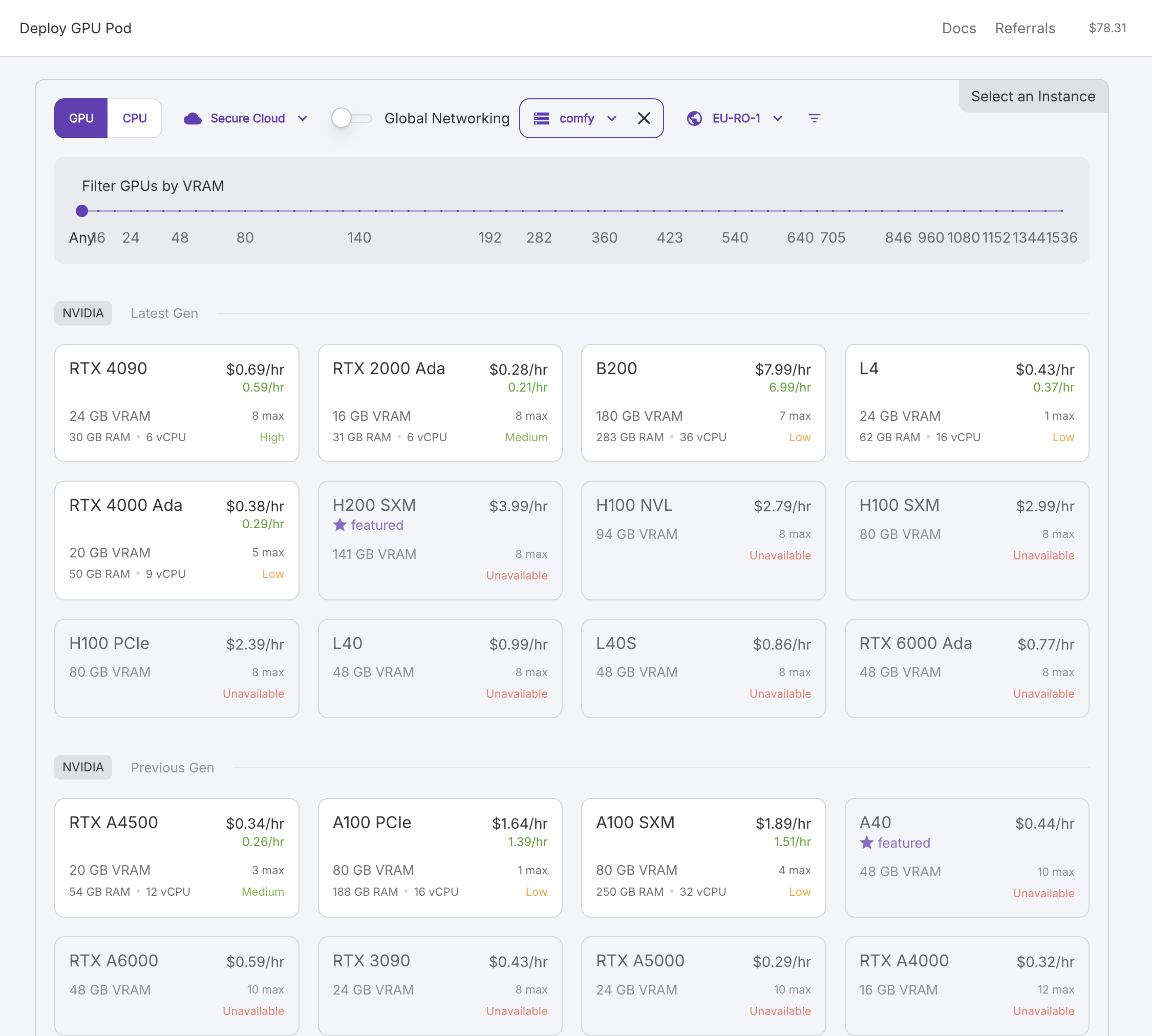
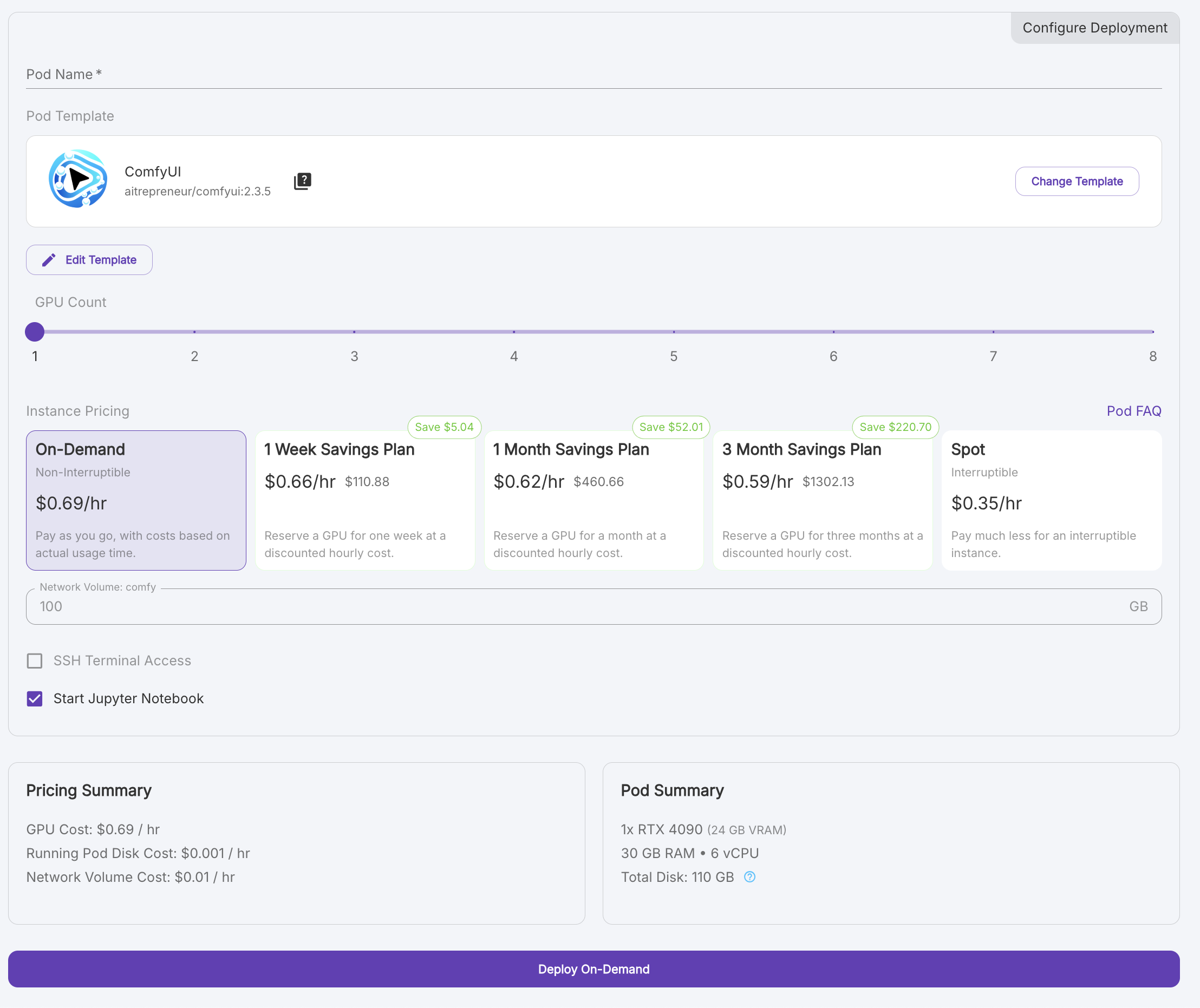
- RTX 4090 auswählen
- Kontrollieren, ob das Network Volume ausgewählt ist (⚠️ kritischer Schritt!)
- Template wählen:
- ComfyUI: aitrepreneur-Template, Sofort einsatzbereit nach dem Hochfahren
- FluxGym: Pytorch 2.2.0, eine Manuelle Installation ist erforderlich (siehe Kapitel Installation)

- Wählen Sie "On-Demand" als Preismodell
- Klicken Sie auf "Deploy On-Demand"
- Nach der Nutzung immer den Pod terminieren (⚠️ Kosteneinsparung!)
Pods lassen sich dank unserer Network-Volume-Methode jederzeit sekundenschnell neu starten
4. Verbindung herstellen
Nach erfolgreicher Installation von ComfyUI sehen Sie die Pod-Übersicht im Reiter „Pods“.
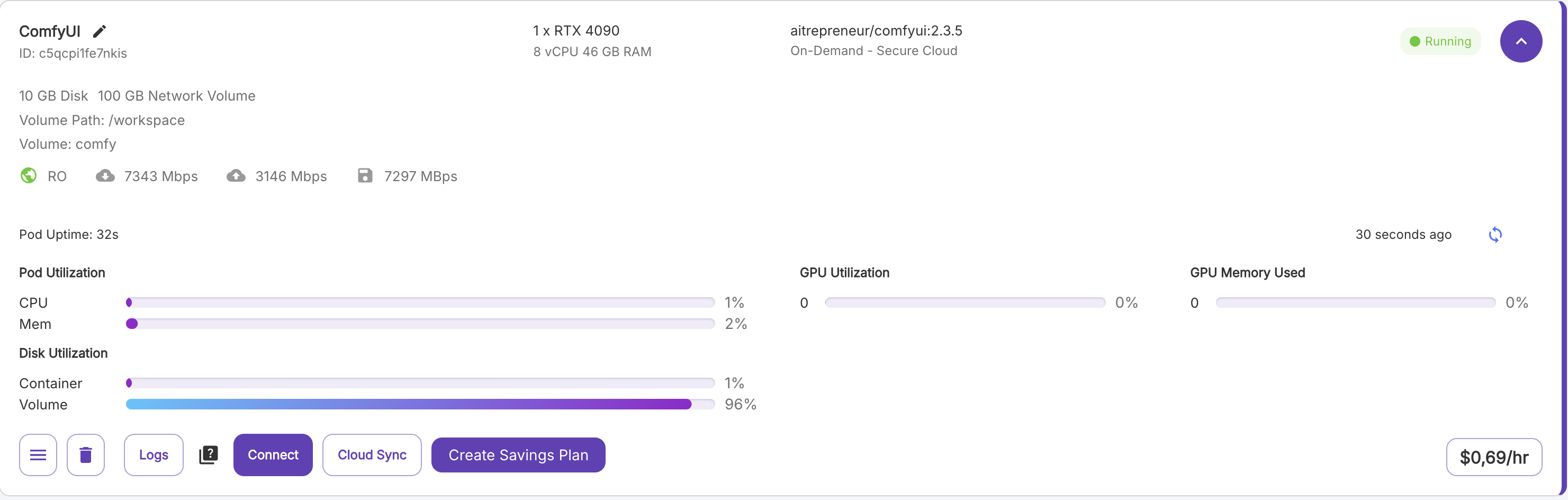
Die abgebildete Instanz zeigt eine Volume-Auslastung von 93%, da bereits verschiedene Bild- und Video-Generatoren installiert wurden.
Klicken Sie auf „Connect“ und warten Sie, bis alle Ports den Status „Ready“ anzeigen.
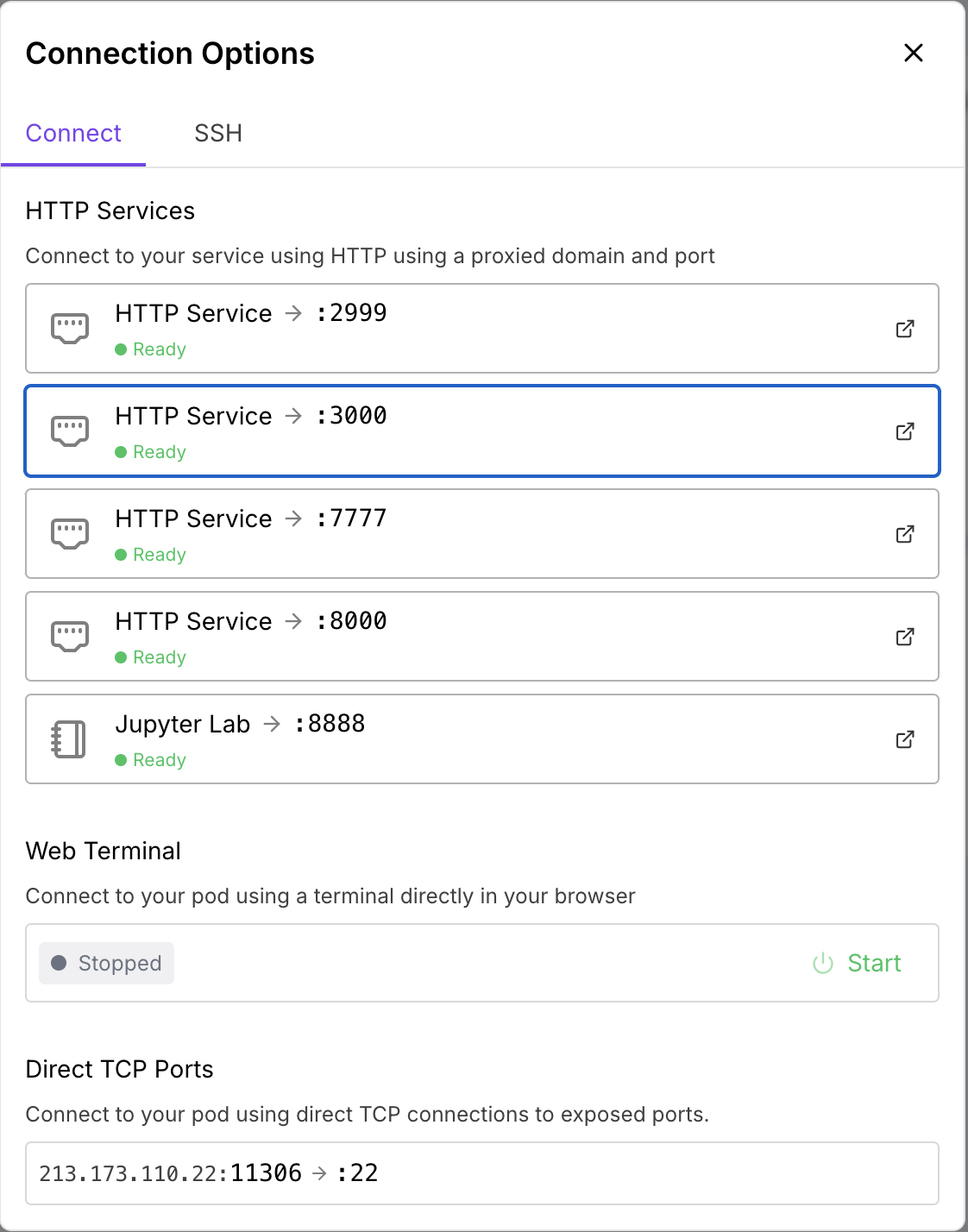
| Connect Port | Internal Port | Description |
|---|---|---|
| 3000 | 3001 | ComfyUI |
| 7777 | 7777 | Code Server |
| 8000 | 8000 | Application Manager |
| 8888 | 8888 | Jupyter Lab |
| 2999 | 2999 | RunPod File Uploader |
Installation
FluxGym Installation
Nachdem wir den Pod erfolgreich aufgesetzt haben und die grundlegenden Voraussetzungen geschaffen wurden, widmen wir uns der Installation von FluxGym. In diesem Abschnitt führen wir Sie Schritt für Schritt durch den Prozess, um FluxGym korrekt einzurichten und betriebsbereit zu machen.
Gehen Sie in das JupyterLab-Interface (Port 8888), öffnen Sie das Terminal und geben Sie die folgenden Befehle ein, um FluxGym zu installieren.
⚠️ Wichtig: Warten Sie nach jedem Befehl, bis die Installation abgeschlossen ist und die Eingabezeile wieder erscheint, bevor Sie fortfahren.

Klonen Sie zunächst FluxGym und kohya-ss/sd-scripts in Ihren 'workspace'-Ordner im JupyterLab.
git clone https://github.com/cocktailpeanut/fluxgym
cd fluxgym
git clone -b sd3 https://github.com/kohya-ss/sd-scriptsIhre Ordnerstruktur wird wie folgt aussehen:
/fluxgym
app.py
requirements.txt
/sd-scriptsAktivieren Sie nun ein virtual environment aus dem Stammverzeichnis von fluxgym
python -m venv env
source env/bin/activateDadurch wird ein env-Ordner direkt unterhalb des fluxgym-Ordners erstellt:
/fluxgym
app.py
requirements.txt
/sd-scripts
/envGehen Sie nun in den Ordner sd-scripts und installieren Sie die Abhängigkeiten in die aktivierte Umgebung:
cd sd-scripts
pip install -r requirements.txtKehren Sie nun zum Stammordner zurück und installieren Sie die Anwendungsabhängigkeiten (aus requirements.txt):
cd ..
pip install -r requirements.txtDie letzte Installation ist pytorch Nightly:
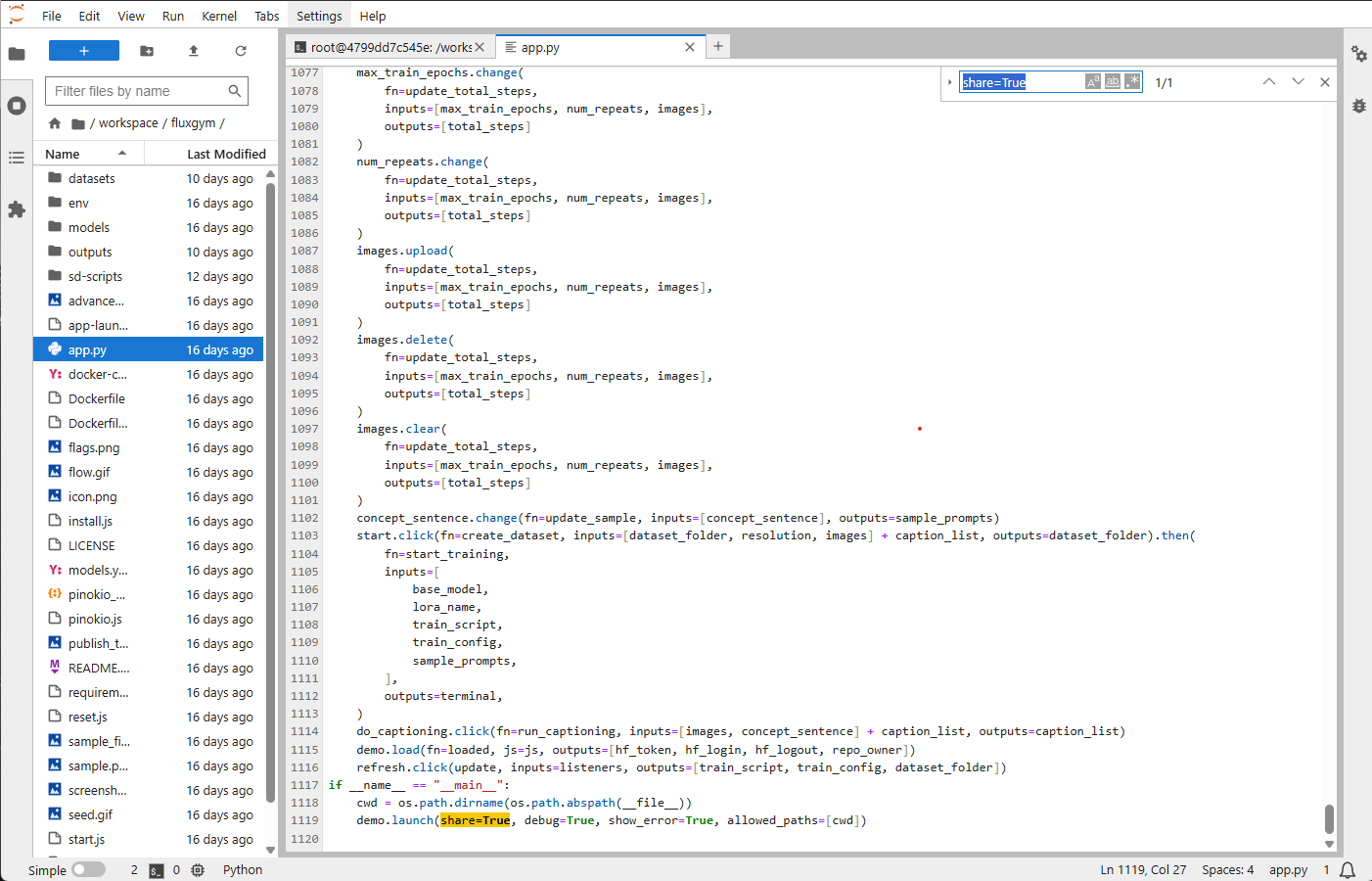
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121Zum Schluss muss im Dokument 'app.py' in Zeile 1119 in der Klammer von 'demo.launch' der Wert 'share=True' hinzugefügt werden, damit beim Start der App ein public Link erstellt wird.
ComfyUI Tutorial
In diesem Kapitel lernen Sie die grundlegende Nutzung von ComfyUI, einer leistungsstarken Benutzeroberfläche für die Erstellung und Verwaltung von Workflows zur Bildgenerierung. ComfyUI ermöglicht es, komplexe Bildgenerierungsprozesse durch ein visuelles Node-System intuitiv zu gestalten und anzupassen. Der Fokus dieses Tutorials liegt darauf, Ihnen die wichtigsten Funktionen und Werkzeuge von ComfyUI näherzubringen. Dabei wird insbesondere der Standard-Workflow erklärt, der die Grundlage für viele kreative Projekte bildet. Sie erfahren, wie die einzelnen Nodes – von der Modellinitialisierung bis zur Bildausgabe – zusammenarbeiten und wie Sie diese effizient nutzen können, um Ihre eigenen Ideen umzusetzen. Dieses Kapitel richtet sich sowohl an Einsteiger, die erste Schritte mit ComfyUI machen möchten, als auch an fortgeschrittene Nutzer, die ihren Workflow optimieren wollen.
Flux Developer Text2Image Workflow mit LoRA Loader
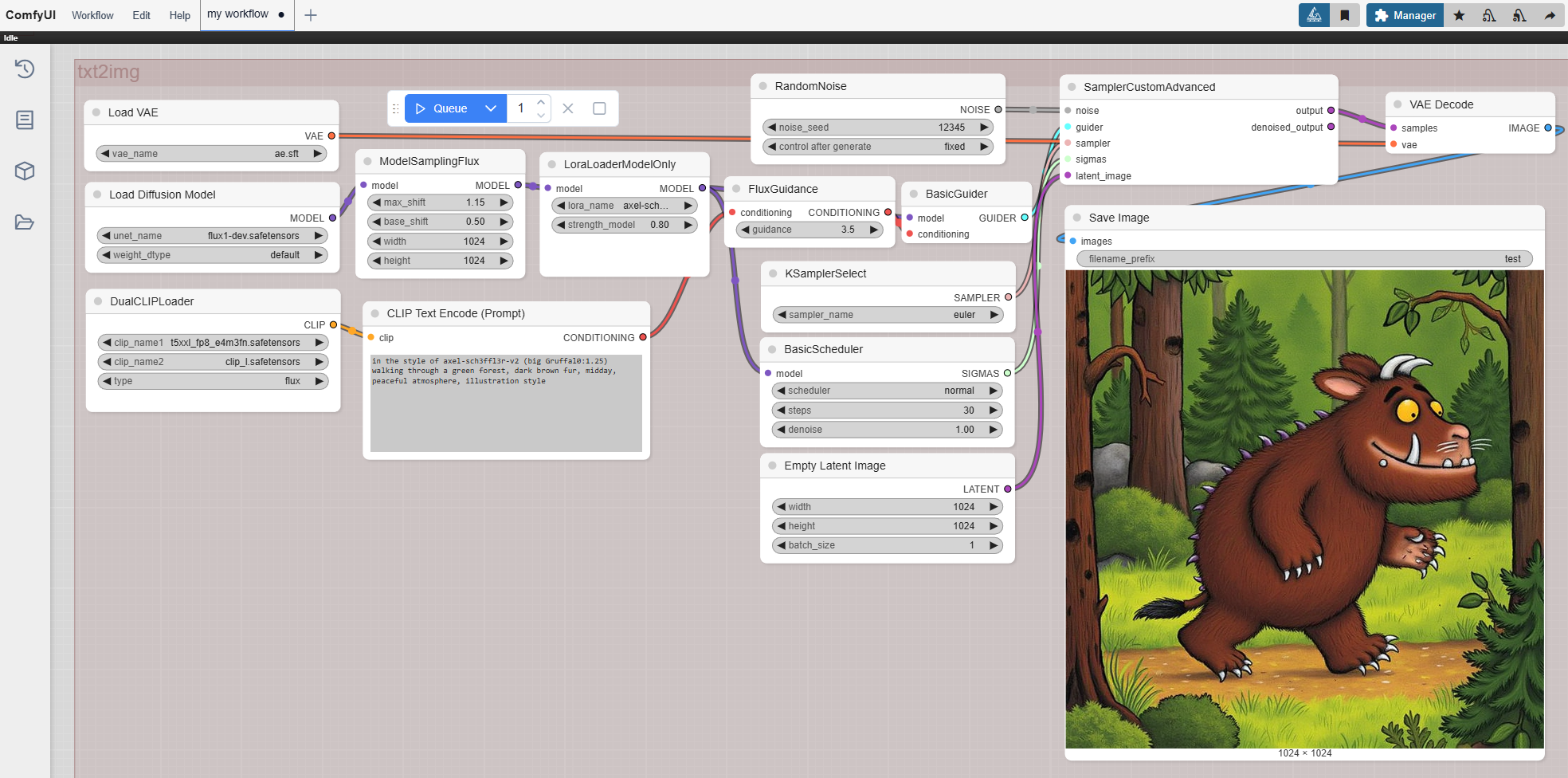
| Node Name | Erklärung | Einstellungsempfehlungen |
|---|---|---|
| Load VAE | Lädt den Variational Autoencoder (VAE), der latente Repräsentationen in Pixelbilder umwandelt. | VAE-Datei: "ae.safetensors". |
| Load Diffusion Model | Lädt das Diffusionsmodell, das den Kern des Bildgenerierungsprozesses bildet. Enthält UNet und andere Komponenten. | Modell: "flux1-dev.safetensors". Gewichtstyp: Standard. |
| Lora-Loader-ModelOnly | Lädt ein LoRA-Modell (Low-Rank Adaptation), um spezifische Aspekte der Bildgenerierung zu modifizieren oder zu verbessern. | LoRA-Modell: "axel-schmidt.safetensors". Stärke des Modells: 0,80. |
| DualCLIPLoader | Lädt zwei CLIP-Modelle gleichzeitig, um Text-Prompts in maschinenlesbare Embeddings umzuwandeln. | CLIP-Modelle: "flxod_fp16.safetensors" und "clip_1.safetensors". Typ: Flux. |
| CLIP Text Encode (Prompt) | Kodiert Text-Prompts in Embeddings, die den Bildgenerierungsprozess steuern. Positive Prompts beschreiben gewünschte Elemente, negative Prompts schließen unerwünschte aus. | Beispiel-Prompt: "Großer Grüffelo, der durch einen grünen Wald spaziert, dunkles braunes Fell, Mittag, friedliche Atmosphäre, Illustrationsstil." |
| RandomNoise | Fügt zufälliges Rauschen hinzu, um den latenten Raum für die Bildgenerierung zu initialisieren. | Rausch-Saat (Seed): 12345. Steuerung nach Generierung: Festgelegt. |
| FluxGuidance | Bietet eine Steuerung, die die Bildgenerierung basierend auf den Eingaben anpasst. | guidance: 3,5. |
| KSamplerSelect | Wählt die Sampling-Methode für das Denoising und die Generierung von Bildern aus latenten Repräsentationen aus. | Sampler-Name: Euler. |
| BasicScheduler | Plant die Denoising-Schritte während der Bildgenerierung. | Anzahl der Schritte: 5. Denoising-Stärke: 1,0. Scheduler-Typ: Normal. |
| Empty Latent Image | Definiert die Dimensionen und Stapelgröße für die Initialisierung des latenten Raums. | Breite: 1024. Höhe: 1024. Stapelgröße (Batch Size): 1. |
| Sampler-Custom-Advanced | Ein benutzerdefinierter Sampler-Knoten für fortgeschrittene Denoising- und Latent-zu-Bild-Konvertierungsprozesse. | Keine spezifischen Einstellungen im Workflow-Bild angegeben. |
| VAE Decode | Dekodiert die latente Repräsentation in ein sichtbares Pixelbild mithilfe des geladenen VAE-Modells. | Nutzt standardmäßig die VAE-Einstellungen des Modells. |
| Save Image | Speichert das generierte Bild mit anpassbaren Dateinamen-Präfixen und Speicherorten. | Dateiname-Präfix: "test". Standard-Speicherort wird verwendet. |
LoRA Training mit FluxGym
FluxGym starten
Überprüfen Sie, ob das Virtual Environment aktiviert ist: Das '(env)-Prefix' sollte in der Terminalzeile sichtbar sein.
Wenn das env aktiv ist, tippen folgenden Befehl um FluxGym zu starten.
cd /workspace/fluxgym
source env/bin/activateWenn das env aktiv ist, tippen folgenden Befehl um FluxGym zu starten.
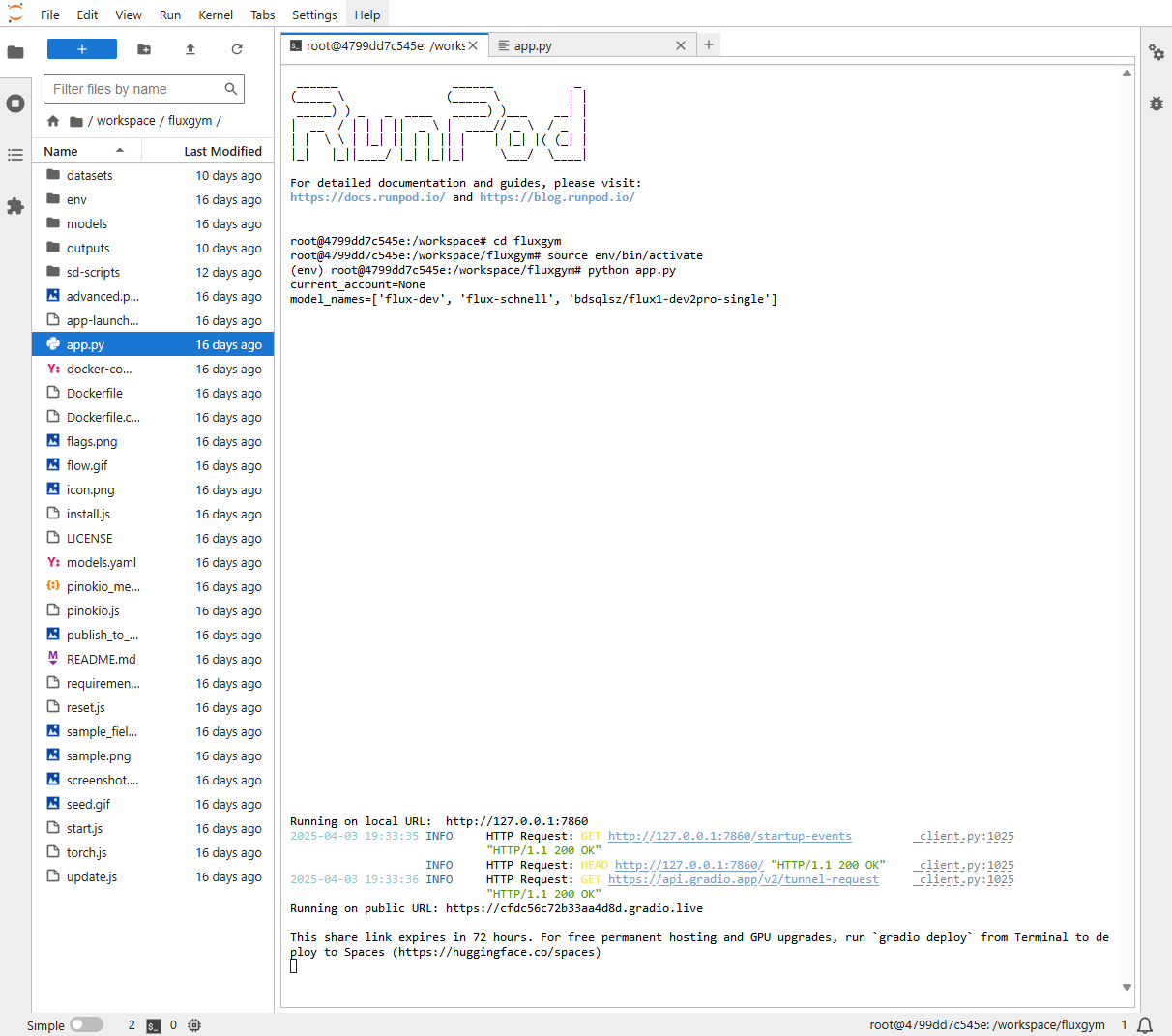
python app.pyDas Ergebnis sollte dann wie folgt aussehen:
Klicken Sie anschließend auf die öffentliche URL, um ins FluxGym-Interface zu gelangen!
Interface und Nutzung
Im FluxGym-Interface angekommen, finden Sie eine in drei Schritte aufgeteilte Benutzeroberfläche. "Step 1: LoRA Info" dient den allgemeinen Trainingseinstellungen, "Step 2: Dataset" dem File-Upload und dem Captioning, und "Step 3: Train" bietet die letzte Möglichkeit, das Trainingsskript zu bearbeiten, bevor Sie oben rechts den Button "Start training" klicken.

| Bereich | Funktion | Beschreibung |
|---|---|---|
| The name of your LoRA | Name des LoRA-Modells | Geben Sie hier den Namen für das LoRA-Modell ein, das erstellt wird. Zum Beispiel: "60erTourismus-Illu-Style". |
| Trigger word/sentence | Schlüsselwort oder Satz | Der Trigger-Begriff oder Satz, der das Modell während der Generierung aktiviert (z. B. "60erTourismus-Illu-Style"). Verwenden Sie eindeutige Begriffe, um Konflikte mit anderen LoRAs zu vermeiden. |
| Base model | Grundmodell auswählen | Wählen Sie das Grundmodell aus, auf dem das Training basiert. Zum Beispiel: "flux-dev". |
| VRAM | VRAM-Auswahl | Wählen Sie die verfügbare VRAM-Größe aus (20GB, 16GB oder 12GB), abhängig von Ihrer Hardware. |
| Repeat trains per image | Anzahl der Wiederholungen pro Bild | Geben Sie an, wie oft jedes Bild während des Trainings wiederholt werden soll. Zum Beispiel: 20. |
| Max Train Epochs | Maximale Anzahl der Epochen | Legen Sie die maximale Anzahl an Trainings-Epochen fest. Zum Beispiel: 16. |
| Expected training steps | Erwartete Trainingsschritte | Anzahl der Schritte, die für das Training benötigt werden. Dieser Wert wird automatisch berechnet (z. B. 6000). |
| Sample image prompts | Beispiel-Prompts für Bilder | Geben Sie Prompts ein, die für die Generierung von Beispielbildern während des Trainings verwendet werden sollen. Trennen Sie mehrere Prompts mit neuen Zeilen (siehe Bild). |
| Sample image every N steps | Bilder nach N Schritten generieren | Legen Sie fest, nach wie vielen Trainingsschritten ein Beispielbild generiert wird. Zum Beispiel: 300. |
| Resize dataset images | Bildergröße anpassen | Legen Sie die Größe fest, auf die die Bilder im Datensatz angepasst werden sollen. Zum Beispiel: 1024. |
| Upload your images | Bilder hochladen | Ziehen Sie Ihre Trainingsbilder per Drag-and-Drop in den Bereich oder klicken Sie auf "Click to Upload", um Dateien auszuwählen. |
| Add AI captions with Florence-2 | Bildbeschriftungen hinzufügen | Nutzt KI-gestützte automatische Beschriftung "Captioning" für hochgeladene Bilder, um relevante Informationen über jedes Bild zu generieren. |
| Train script | Skript für das Training auswählen | Legen Sie hier den Pfad zum Trainingsskript fest, das verwendet werden soll (siehe Bild). |
| Train config | Trainingskonfiguration einstellen | Passen Sie verschiedene Parameter wie Auflösung, Batchgröße und Wiederholungen an. Zum Beispiel: Auflösung = 1024, Batch size = 1. |
| Train log (Advanced options) | Detaillierte Protokollierung aktivieren | Aktivieren Sie diese Option, um detaillierte Protokolle während des Trainings zu erhalten. |
| Samples | Anzeigen von Beispielbildern | Sobald das Training läuft, werden hier die generierten Beispielbilder angezeigt. |